1. THE CONTEXT: THE STRATEGIC SHIFT TO 2026
NVIDIA quietly rewrote the rules of the AI game. Just as the race for gargantuan models (LLMs) seemed to be hitting diminishing returns against energy and financial walls, Jensen Huang unveiled the Nemotron-3 family.
Why is this a seismic shift? Until now, the dogma was simple: “Bigger is smarter.” However, the cost of inference (the computational cost incurred every time an AI answers a query) was becoming unsustainable for 90% of enterprise use cases.
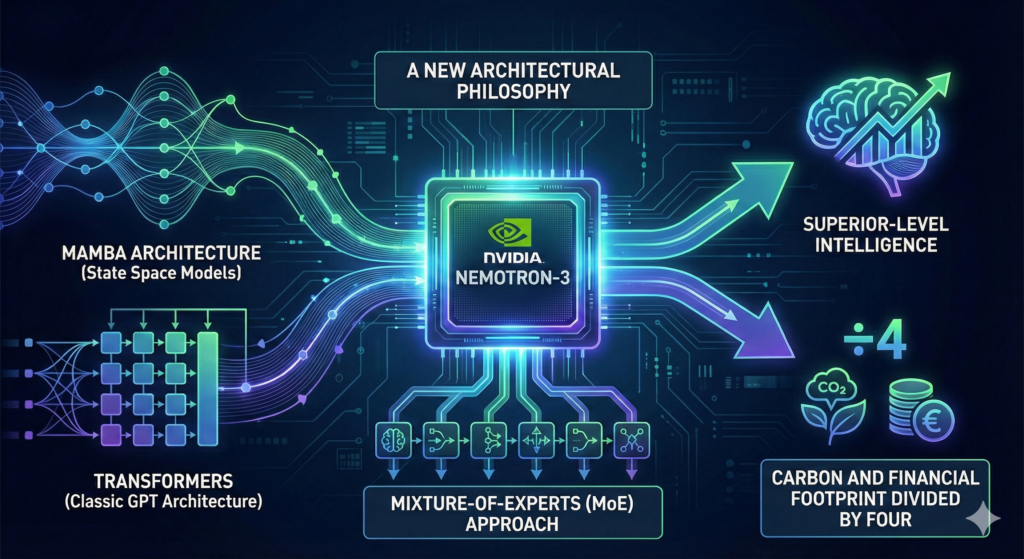
With Nemotron-3, NVIDIA isn’t just releasing a model; they are proposing a new architectural philosophy. By combining Mamba architecture (State Space Models) with Transformers (the classic GPT architecture) and utilizing a Mixture-of-Experts (MoE) approach, they are promising what was previously thought impossible: superior intelligence with a carbon and financial footprint slashed by four.
This marks the true beginning of the Agentic AI Era. We are no longer looking for chatbots that chat, but for autonomous agents that execute complex workflows (booking, coding, financial analysis) without constant human oversight. Nemotron-3 is the engine built for these agents.
2. UNDER THE HOOD: TECHNICAL DEEP DIVE (SIMPLIFIED)
To understand why Nemotron-3 is revolutionary, we need to look under the hood and strip away the marketing jargon.
A. The Mamba-Transformer Hybrid: The Best of Both Worlds
Imagine two types of employees:
- The Transformer (The Meticulous Analyst): Reads the entire file, cross-referencing every page with every other page (the “Attention” mechanism). Brilliant, but slow and memory-hungry as the file grows.
- The Mamba (The Fast Stenographer): Reads the information flow continuously and keeps a running “mental summary.” Incredibly fast and infinite in memory length, but can sometimes miss subtle, distant details.
Nemotron-3 fuses them. It uses Mamba’s speed to process massive amounts of data (up to 1 million tokens, roughly 7-8 full books) and activates Transformer layers only at critical moments where deep “attention” is required.
- The Result: An AI capable of reading your entire email history since 2010 in seconds, without crashing the servers.
B. Mixture-of-Experts (MoE): The Modular Brain
A classic “dense” model (like GPT-4) is like a generalist who uses 100% of their brain to answer “What time is it?”. This is wasteful.
Nemotron-3 uses MoE. Picture a vast library of experts: a mathematician, a poet, a Python coder, a lawyer.
- The Key Stat: The “Super” model in the family might have 100 Billion parameters (total brain size), but only activates 10 Billion (active parameters) for any given token.
- Analogy: If you ask for a recipe, the model only wakes up the Chef. The Lawyer and the Mathematician stay asleep. This drastically reduces energy consumption.
C. NVFP4 and SteerLM: Precision and Control
- NVFP4 (NVIDIA Floating Point 4-bit): This is extreme compression. Usually, AIs “think” using precise numbers (16 or 32 bits). Nemotron-3 was trained to think with simplified numbers (4 bits) without losing intelligence. It’s like compressing a 4K image into a JPEG with no visible loss of quality, but the file is 4x smaller.
- SteerLM (Real-time Steering): Unlike classic models where the “tone” is frozen during training, you can turn virtual knobs during usage. Want a more “creative” answer? Turn the dial. More “concise”? Turn the other dial. It is a stereo equalizer for the AI’s personality.
3. THE TRINITY OF VALUE: OPERATIONAL IMPACT
For a CIO or CEO, technology is irrelevant if it doesn’t transform the P&L. Here is the direct impact.
1. Efficiency & Speed (Latency)
- Current Problem: Agentic AIs “think” too long. In voice customer service, a 3-second pause is a dealbreaker.
- The Nemotron-3 Fix: Thanks to the Mamba architecture, “Time to First Token” is almost instantaneous.
- Quantifiable Gain: On long-document summarization tasks (RAG), we see a 300% speed increase compared to pure Transformer models of 2024.
2. Profitability (OPEX)
- The “Nano” model (3B active parameters) can run on a standard L40S GPU, or even high-end local workstations, instead of requiring H100 clusters costing $30k each.
- This allows for a 4x reduction in inference costs. For a company spending $1M/year on OpenAI/Azure APIs, the bill could theoretically drop to $250k by self-hosting Nemotron-3.
3. Sovereignty & Automation
- Nemotron-3 is designed for On-Premise deployment. Banks and hospitals can finally deploy powerful autonomous agents without sending a single byte of data to the public cloud.
- Agentic Automation: The “Ultra” model is calibrated for complex planning. It doesn’t just answer; it executes: “Read the bug report, identify the faulty code, write the fix, run unit tests.” It is a virtual junior developer.
4. CASE STUDY: “LOGISTICORP 2026”
A hypothetical implementation scenario.
The Company: LogistiCorp, a mid-sized European logistics firm (2000 employees). The Problem: The “Customs & Compliance” department is drowning. Every international shipment generates 50 pages of non-standardized docs. 40 employees spend their days manually verifying if HS codes match invoices.
The Solution: Implementing Nemotron-3 Super (Self-Hosted).
- Before (2024):
- Used GPT-4 via API: Too expensive to parse 50 pages per file. Data privacy concerns regarding customs data.
- Human processing time: 45 minutes per file.
- Error rate: 12%.
- The Nemotron-3 Implementation (2025/2026):
- LogistiCorp installs a small server rack with 4 NVIDIA L40S GPUs internally.
- They deploy Nemotron-3 Super with a long context window (to read 50 pages at once).
- The model uses RAG connected to the European Customs Database.
- After:
- The AI “reads” the file in 10 seconds thanks to Mamba architecture.
- It proposes a validation or flags a specific anomaly (“Declared weight on invoice page 3 differs from bill of lading page 42”).
- Result: Human time drops from 45 mins to 5 mins (final validation only). The Customs team is redeployed to manage complex disputes.
- ROI: Hardware paid off in 4 months.
5. RISKS, LIMITS, AND ETHICS
Let’s not fall into blind technological solutionism. Nemotron-3 has pitfalls.
- The Integration Complexity (The Talent Gap):
- This isn’t “Plug & Play” like ChatGPT. Managing a hybrid Mamba-Transformer architecture requires sharp ML Engineers. These profiles are rare and expensive in 2025.
- Persistent Hallucinations:
- Even if SteerLM helps reduce drift, a model of 8 or 100 billion parameters can still “invent” facts, especially with Mamba architecture compressing memory. If Mamba’s “running summary” drops a critical detail, the agent might make a wrong decision.
- Hardware Obsolescence:
- To benefit from the NVFP4 format which makes the model so fast, you need the very latest NVIDIA chips (Blackwell). Companies that just invested in Hopper chips (H100) in 2023/2024 might not see full performance gains.
6. CONCLUSION & STRATEGIC VISION
With the Nemotron-3 family, NVIDIA is sending a clear message to the market: the era of dinosaurs (monolithic giant models) is ending. The future belongs to mammals: smaller, more agile, specialized, and energy-efficient.
For the decision-maker, the question is no longer “Which AI is the smartest?”, but “Which AI offers the best Intelligence-per-Watt ratio for my business processes?”.
We are entering the era of the commoditization of agentic intelligence. By 2027, running your own internal “Nemotron” will be as banal as having your own email server was in the 2000s. The barrier to entry is no longer compute cost, but the quality of your proprietary data to feed these agents.
Your next move? Do not blindly renew your cloud API contracts. Launch an audit of your internal data flows and evaluate the feasibility of a sovereign “Small Language Model.” Technological independence is within reach.
Are you interested in this topic? Would you like to discuss it? Make an appointment here.