1. LE CONTEXTE : LA RUPTURE STRATÉGIQUE DE DÉCEMBRE 2025
A l’aube de 2026, NVIDIA a silencieusement redéfini les règles du jeu. Alors que la course aux modèles gargantuesques (les LLMs ou Large Language Models) semblait s’essouffler face aux murs énergétiques et financiers, Jensen Huang a dévoilé la famille Nemotron-3.
Pourquoi est-ce un séisme ? Jusqu’ici, le dogme était simple : « Plus c’est gros, plus c’est intelligent ». GPT-5 et ses concurrents ont prouvé que cette loi avait des rendements décroissants. Le coût de l’inférence (le moment où l’IA « réfléchit » pour vous répondre) devenait insoutenable pour 90% des entreprises.
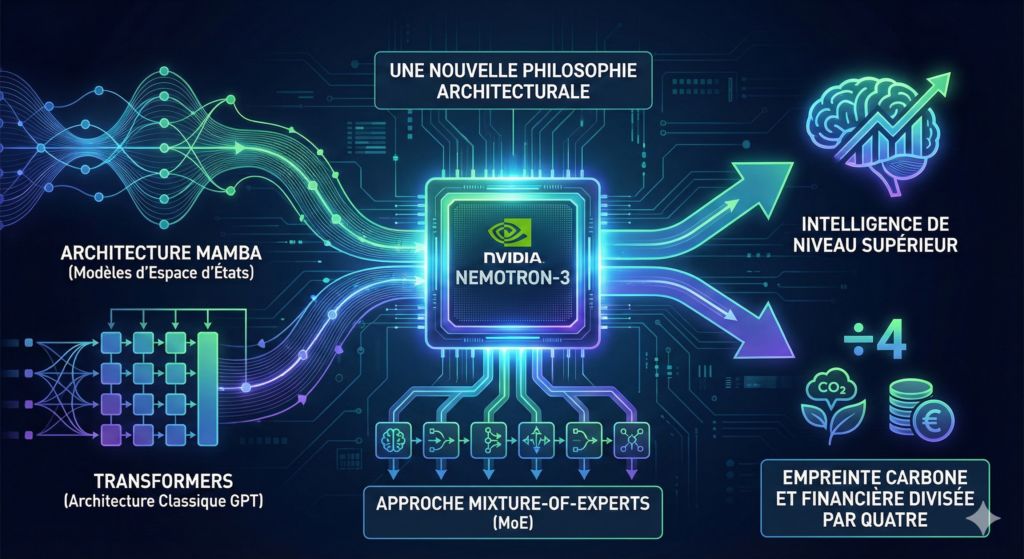
Avec Nemotron-3, NVIDIA ne propose pas seulement un modèle, mais une nouvelle philosophie architecturale. En combinant l’architecture Mamba (modèles d’espace d’états) et les Transformers (l’architecture classique de GPT), et en utilisant une approche « Mixture-of-Experts » (MoE), ils promettent l’impossible : une intelligence de niveau supérieur avec une empreinte carbone et financière divisée par quatre.
C’est l’ère de l’IA Agentique. Nous ne cherchons plus des chatbots qui discutent, mais des agents autonomes qui exécutent des tâches complexes (réservation, codage, analyse financière) sans surveillance humaine constante. Nemotron-3 est le moteur conçu pour ces agents.
2. SOUS LE CAPOT : ANALYSE TECHNIQUE VULGARISÉE
Pour comprendre pourquoi Nemotron-3 est révolutionnaire, il faut ouvrir le capot et oublier le jargon marketing. Voici ce qui change réellement.
A. L’Hybride Mamba-Transformer : Le Meilleur des Deux Mondes
Imaginez deux types d’employés :
- Le Transformer (L’Analyste Méticuleux) : Il lit tout le dossier, compare chaque page avec chaque autre page (c’est le mécanisme d' »Attention »). Il est brillant mais très lent et demande une mémoire énorme si le dossier est épais.
- Le Mamba (Le Sténotypiste Rapide) : Il lit le flux d’information en continu et garde un « résumé courant » en tête. Il est incroyablement rapide et ne sature jamais sa mémoire, mais il peut parfois manquer des détails subtils lointains.
Nemotron-3 fusionne les deux. Il utilise la vitesse de Mamba pour traiter d’énormes quantités de données (jusqu’à 1 million de tokens, soit environ 7 à 8 livres entiers) et active les couches Transformer uniquement aux moments critiques où une « attention » profonde est nécessaire.
- Résultat : Une IA capable de lire tout l’historique de vos emails depuis 2010 en quelques secondes, sans faire exploser les serveurs.
B. Mixture-of-Experts (MoE) : Le Cerveau Modulaire
Un modèle classique « dense » (comme GPT-3) est comme un généraliste qui utilise 100% de son cerveau pour répondre à « Quelle heure est-il ? ». C’est du gaspillage.
Nemotron-3 utilise le MoE. Imaginez une immense bibliothèque d’experts : un mathématicien, un poète, un codeur Python, un juriste.
- Le Chiffre Clé : Le modèle « Super » de la gamme possède 100 milliards de paramètres (la taille totale du cerveau), mais n’en utilise que 10 milliards (les paramètres « actifs ») pour chaque tâche.
- Analogie : Si vous demandez une recette de cuisine, le modèle ne « réveille » que le chef cuisinier. Le juriste et le mathématicien restent endormis. Cela réduit drastiquement la consommation d’énergie.
C. NVFP4 et SteerLM : Précision et Contrôle
- NVFP4 (NVIDIA Floating Point 4-bit) : C’est une méthode de compression extrême. Habituellement, les IA « pensent » avec des nombres très précis (16 ou 32 bits). Nemotron-3 a été entraîné pour penser avec des nombres simplifiés (4 bits) sans perdre en intelligence. C’est comme compresser une image 4K en JPEG sans perte visible de qualité, mais le fichier est 4x plus léger.
- SteerLM (Pilotage en temps réel) : Contrairement aux modèles classiques où le « ton » est figé à l’entraînement, vous pouvez tourner des boutons virtuels pendant l’utilisation. Vous voulez une réponse plus « créative » ? Tournez le bouton. Plus « concise » ? Tournez l’autre. C’est un égaliseur audio pour la personnalité de l’IA.
3. L’IMPACT OPÉRATIONNEL : LA TRINITÉ DE LA VALEUR
Pour un CIO (DSI) ou un CEO, la technologie importe peu si elle ne transforme pas le P&L (Compte de résultat). Voici l’impact direct.
1. Efficacité & Vitesse (Latence)
- Le problème actuel : Les agents IA « réfléchissent » trop longtemps. Dans un service client vocal, une pause de 3 secondes est gênante.
- L’apport Nemotron-3 : Grâce à l’architecture Mamba, le « Time to First Token » (temps avant le premier mot) est quasi instantané.
- Gain chiffré : Sur des tâches de résumé de documents longs (RAG), on observe une accélération de 300% par rapport aux modèles Transformer purs de 2024.
2. Rentabilité (OPEX)
- Le modèle « Nano » (3 milliards de paramètres actifs) peut tourner sur une carte graphique L40S standard, voire sur des stations de travail locales haut de gamme, au lieu de nécessiter des clusters H100 à 30 000 $ l’unité.
- Cela permet de diviser par 4 les coûts d’inférence. Pour une entreprise qui dépense 1M€/an en API OpenAI/Azure, la facture pourrait théoriquement descendre à 250k€ en hébergeant Nemotron-3 en interne (Self-hosted).
3. Souveraineté & Automatisation
- Nemotron-3 est conçu pour le « On-Premise » (sur site). Les banques et hôpitaux peuvent enfin déployer des agents autonomes puissants sans envoyer un seul octet de donnée vers le cloud public américain.
- L’Automatisation Agentique : Le modèle « Ultra » est calibré pour la planification complexe. Il ne se contente pas de répondre, il peut : « Lire le rapport de bug, identifier le code fautif, écrire le correctif, lancer les tests unitaires ». C’est un collaborateur junior virtuel.
4. ÉTUDE DE CAS : « LOGISTICORP 2026 »
Scénario fictif d’implémentation.
L’Entreprise : LogistiCorp, un transporteur européen de taille moyenne (2000 employés). Le Problème : Le service « Douanes & Conformité » est noyé. Chaque expédition internationale génère 50 pages de documents non standardisés. 40 employés passent leur journée à vérifier manuellement si les codes HS (codes douaniers) correspondent aux factures.
La Solution : Implémentation de Nemotron-3 Super (Self-Hosted).
- Avant (2024) :
- Utilisation de GPT-4 via API : Trop cher pour analyser 50 pages par dossier. Confidentialité des données douanières problématique.
- Temps de traitement humain : 45 minutes par dossier.
- Erreurs : 12%.
- L’Implémentation Nemotron-3 (2025/2026) :
- LogistiCorp installe un petit serveur avec 4 cartes NVIDIA L40S en interne.
- Ils déploient Nemotron-3 Super avec un contexte long (pour lire les 50 pages d’un coup).
- Le modèle utilise le mécanisme RAG (Retrieval Augmented Generation) connecté à la base de données des codes douaniers européens.
- Après :
- L’IA « lit » le dossier en 10 secondes grâce à l’architecture Mamba.
- Elle propose une validation ou signale une anomalie précise (« Le poids déclaré sur la facture page 3 diffère du bon de livraison page 42 »).
- Résultat : Le temps humain passe de 45 min à 5 min (juste la validation finale). L’équipe « Douanes » est redéployée sur la gestion des litiges complexes.
- ROI : Rentabilisation du matériel en 4 mois.
5. RISQUES, LIMITES ET ÉTHIQUE
Ne tombons pas dans le solutionnisme technologique aveugle. Nemotron-3 comporte des pièges.
- La Complexité d’Intégration (Le « Talent Gap ») :
- Ce n’est pas du « Plug & Play » comme ChatGPT. Gérer une architecture hybride Mamba-Transformer demande des ingénieurs ML (Machine Learning) pointus. Ces profils sont rares et chers en 2025.
- Les Hallucinations Persistantes :
- Même si le SteerLM aide à réduire les dérapages, un modèle de 8 ou 100 milliards de paramètres peut encore « inventer » des faits, surtout avec l’architecture Mamba qui compresse la mémoire. Si le « résumé courant » de Mamba oublie un détail critique, l’agent peut prendre une décision erronée.
- L’Obsolescence Matérielle :
- Pour profiter du format NVFP4 (4-bits) qui rend le modèle si rapide, il faut les toutes dernières puces NVIDIA (Blackwell). Les entreprises qui viennent d’investir dans des puces Hopper (H100) en 2023/2024 pourraient ne pas voir tous les gains de performance.
6. CONCLUSION & VISION STRATÉGIQUE
Avec la famille Nemotron-3, NVIDIA envoie un message clair au marché : l’époque des dinosaures (les modèles monolithiques géants) touche à sa fin. L’avenir appartient aux mammifères : plus petits, plus agiles, spécialisés et économes en énergie.
Pour le décideur, la question n’est plus « Quelle IA est la plus intelligente ? », mais « Quelle IA offre le meilleur ratio Intelligence/Watt pour mes processus métier ? ».
Nous entrons dans l’ère de la commoditisation de l’intelligence agentique. D’ici 2027, avoir son propre « Nemotron » en interne sera aussi banal qu’avoir son propre serveur email dans les années 2000. La barrière à l’entrée n’est plus le coût du calcul, mais la qualité de vos données propriétaires pour nourrir ces agents.
Votre prochaine action ? Ne renouvelez pas vos contrats API cloud aveuglément. Lancez un audit de vos flux de données internes et évaluez la faisabilité d’un modèle « Small Language Model » souverain. L’indépendance technologique est à portée de main.
Vous désirez en parler ? Ce sujet vous interpelle ? Prenez Rendez-vous ICI